|
Jun Hao Liew I am a senior research scientist at TikTok/ByteDance Research. My research focus is controllable diffusion-based generative models. Before joining TikTok, I worked as a research fellow at NUS. Prior to that, I did my Ph.D. with A/P Sim-Heng Ong, Dr. Wei Xiong and Dr. Jiashi Feng in NUS. I am actively looking for research interns and collaborators. Please feel free to drop me an email if you are interested. Email / Google Scholar / LinkedIn / Twitter / Github |

|
Publications |
|
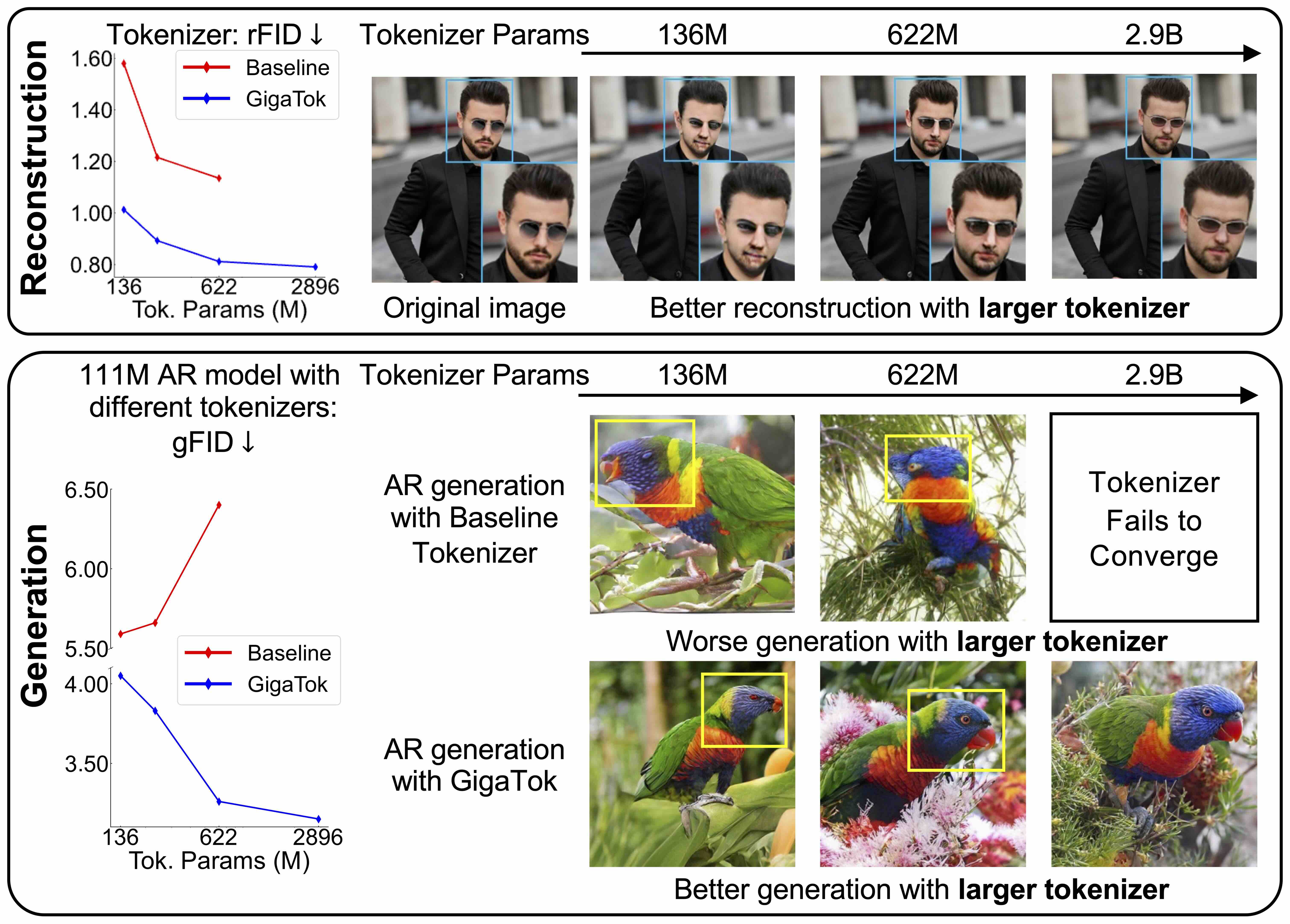
GigaTok: Scaling Visual Tokenizers to 3 Billion Parameters for Autoregressive Image Generation
Tianwei Xiong, Jun Hao Liew, Zilong Huang, Jiashi Feng, Xihui Liu ICCV, 2025 project page / code / arXiv We introduce GigaTok, the first method for scaling visual tokenizers to 3 billion parameters. |
|
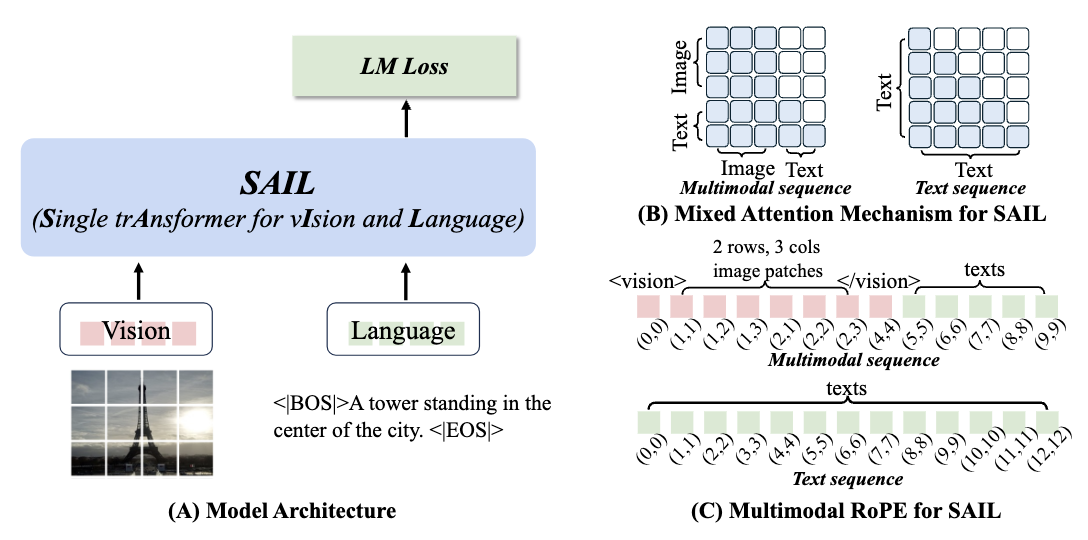
The Scalability of Simplicity: Empirical Analysis of Vision-Language Learning with a Single Transformer
Weixian Lei*, Jiacong Wang*, Haochen Wang*, Xiangtai Li, Jun Hao Liew, Jiashi Feng, Zilong Huang ICCV, 2025 *Highlight code / arXiv We systematically compare SAIL’s properties—including scalability, cross-modal information flow patterns, and visual representation capabilities—with those of modular MLLMs. |

|
LightningDrag: Lightning Fast and Accurate Drag-based Image Editing Emerging from Videos
Yujun Shi*, Jun Hao Liew*, Hanshu Yan, Vincent Y. F. Tan, Jiashi Feng ICML, 2025 project page / code / arXiv / HuggingFace demo We train a fast (<1s) and accurate drag-based image editing model by learning from video supervision. |

|
DiG: Scalable and Efficient Diffusion Models with Gated Linear Attention
Lianghui Zhu, Zilong Huang, Bencheng Liao, Jun Hao Liew, Hanshu Yan, Jiashi Feng, Xinggang Wang CVPR, 2025 code / arXiv This work presents Diffusion GLA, the first exploration for diffusion backbone with linear attention transformer. |
|
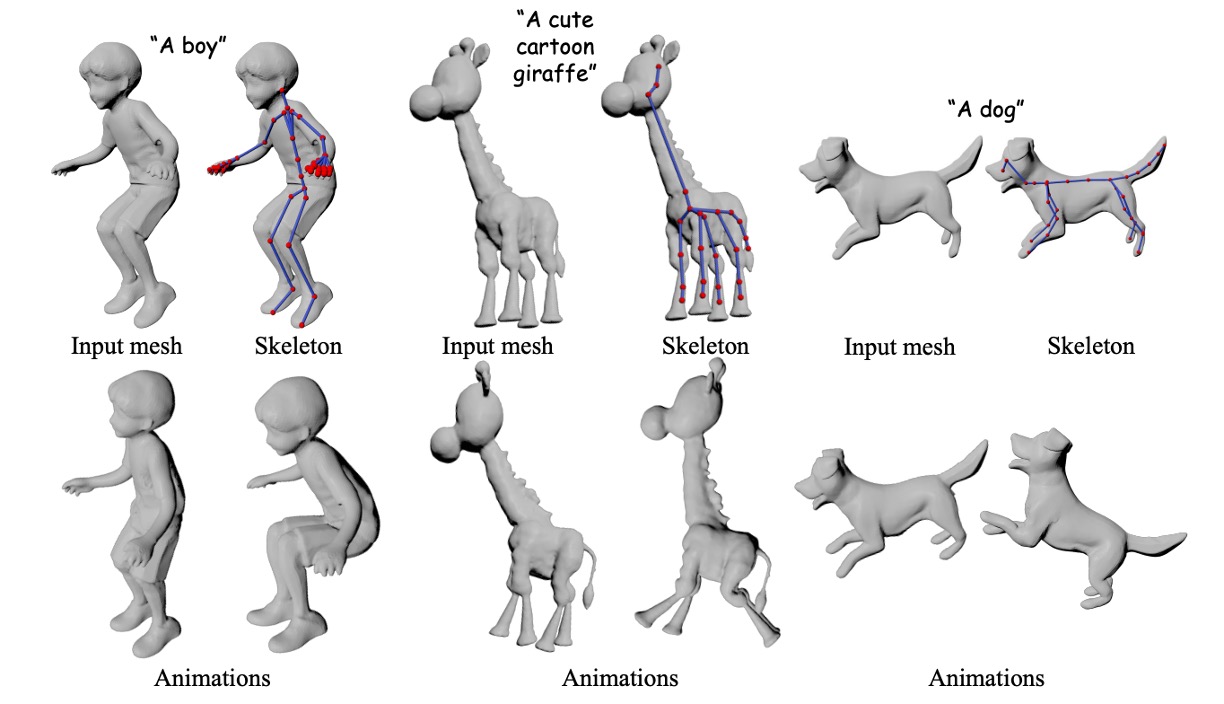
MagicArticulate: Make Your 3D Models Articulation-Ready
Chaoyue Song, Jianfeng Zhang, Xiu Li, Fan Yang, Yiwen Chen, Zhongcong Xu, Jun Hao Liew, Xiaoyang Guo, Fayao Liu, Jiashi Feng, Guosheng Lin CVPR, 2025 project page / code / arXiv Given an input mesh, MagicArticulate first generates skeleton autoregressively and then predicts skinning weights, making it articulation-ready. |

|
ClassDiffusion: More Aligned Personalization Tuning with Explicit Class Guidance
Jiannan Huang, Jun Hao Liew, Hanshu Yan, Yuyang Yin, Yao Zhao, Yunchao Wei ICLR, 2025 project page / code / arXiv We present ClassDiffusion to mitigate the weakening of compositional ability during personalization tuning. |
|
|
AvatarStudio: High-fidelity and Animatable 3D Avatar Creation from Text
Jianfeng Zhang*, Xuanmeng Zhang*, Huichao Zhang, Jun Hao Liew, Chenxu Zhang, Yi Yang, Jiashi Feng IJCV, 2025 project page / code / arXiv We propose AvatarStudio, a coarse-to-fine generative model that generates explicit textured 3D meshes for animatable human avatars. |
|
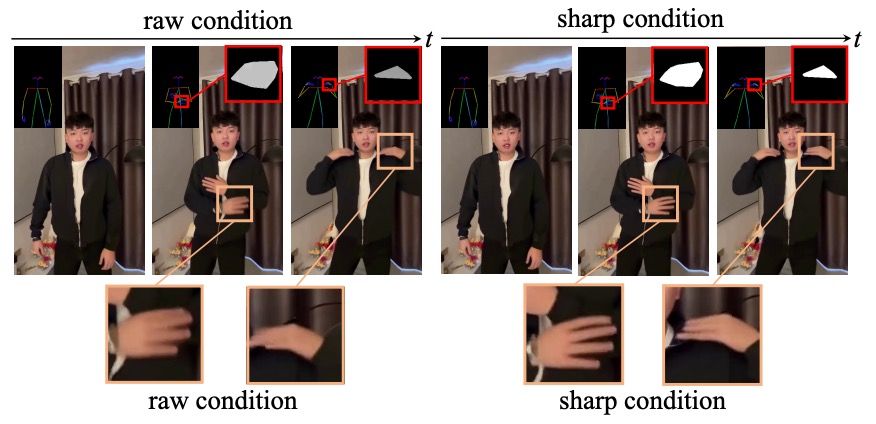
High Quality Human Image Animation using Regional
Supervision and Motion Blur Condition
Zhongcong Xu*, Chaoyue Song*, Guoxian Song*, Jianfeng Zhang, Jun Hao Liew, Hongyi Xu, You Xie, Linjie Luo, Guosheng Lin, Jiashi Feng, Mike Zheng Shou arXiv, 2024 arXiv We improve the appearance quality of MagicAnimate by introducing regional supervision and explicit modeling of motion blur. |

|
Empowering Visual Creativity: A Vision-Language Assistant to Image Editing Recommendations
Tiancheng Shen, Jun Hao Liew, Long Mai, Lu Qi, Jiashi Feng, Jiaya Jia arXiv, 2024 arXiv We present Creativity-VLM, a vision-language assistant that can translate coarse editing hints (e.g., "spring") into precise, actionable instructions for image editing. |
|
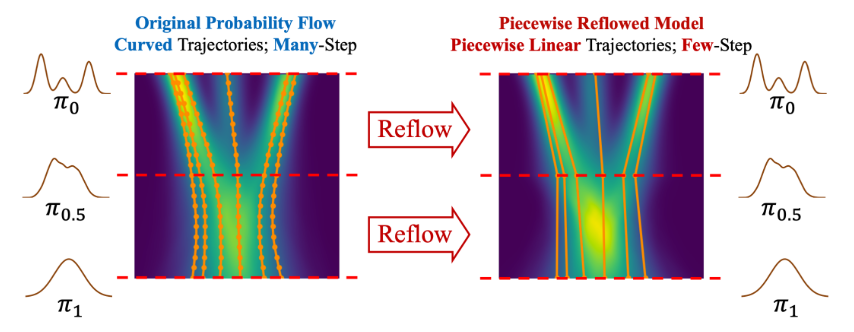
PeRFlow: Piecewise Rectified Flow as Universal Plug-and-Play Accelerator
Hanshu Yan, Xingchao Liu, Jiachun Pan, Jun Hao Liew, Qiang Liu, Jiashi Feng NeurIPS, 2024 project page / code / arXiv We present PeRFlow, a flow-based method for accelerating diffusion models. |
|
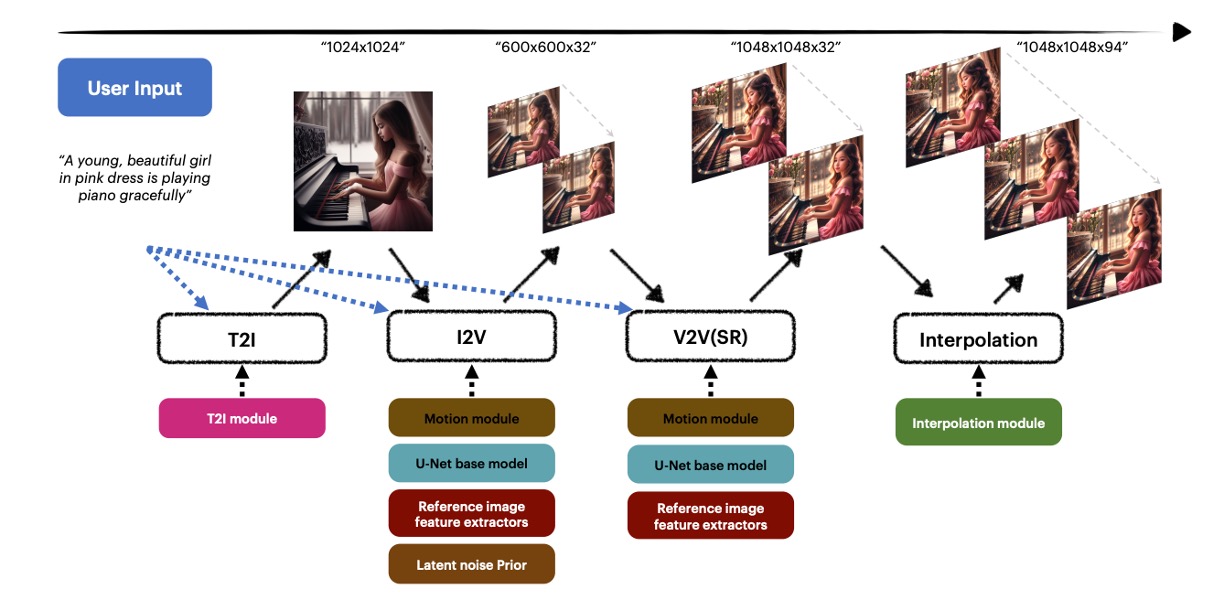
MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation
Weimin Wang*, Jiawei Liu*, Zhijie Lin, Jiangqiao Yan, Shuo Chen, Chetwin Low, Tuyen Hoang, Jie Wu, Jun Hao Liew, Hanshu Yan, Daquan Zhou, Jiashi Feng arXiv, 2024 project page / arXiv MagicVideo-V2 integrates text-to-image model, video motion generator, reference image embedding module and frame interpolation module into an end-to-end video generation pipeline. |
|
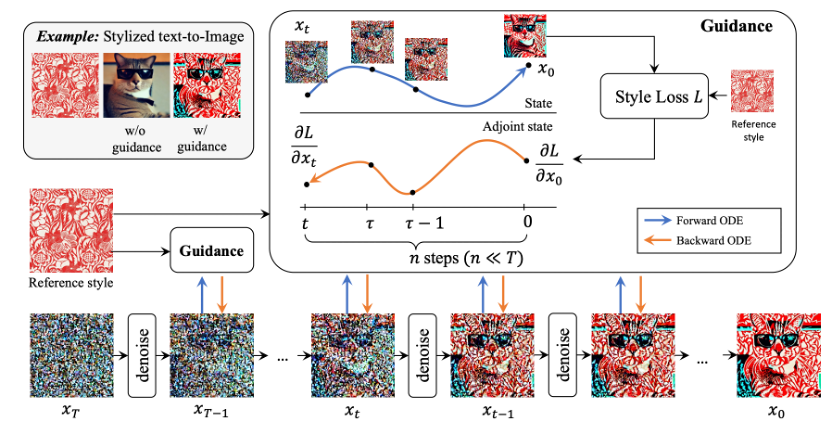
Towards Accurate Guided Diffusion Sampling through Symplectic Adjoint Method
Jiachun Pan*, Hanshu Yan*, Jun Hao Liew, Jiashi Feng, Vincent V. F. Tan arXiv, 2023 code / arXiv We present Symplectic Adjoint Guidance (SAG) to obtain accurate gradient guidance for training-free guided sampling in diffusion models. |
|
DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing
Yujun Shi, Chuhui Xue, Jun Hao Liew, Jiachun Pan, Hanshu Yan, Wenqing Zhang, Vincent Y. F. Tan, Song Bai CVPR, 2024 *Highlight project page / code / arXiv We present DragDiffusion, which extends interactive point-based image editing to large-scale pretrained diffusion models. |
|
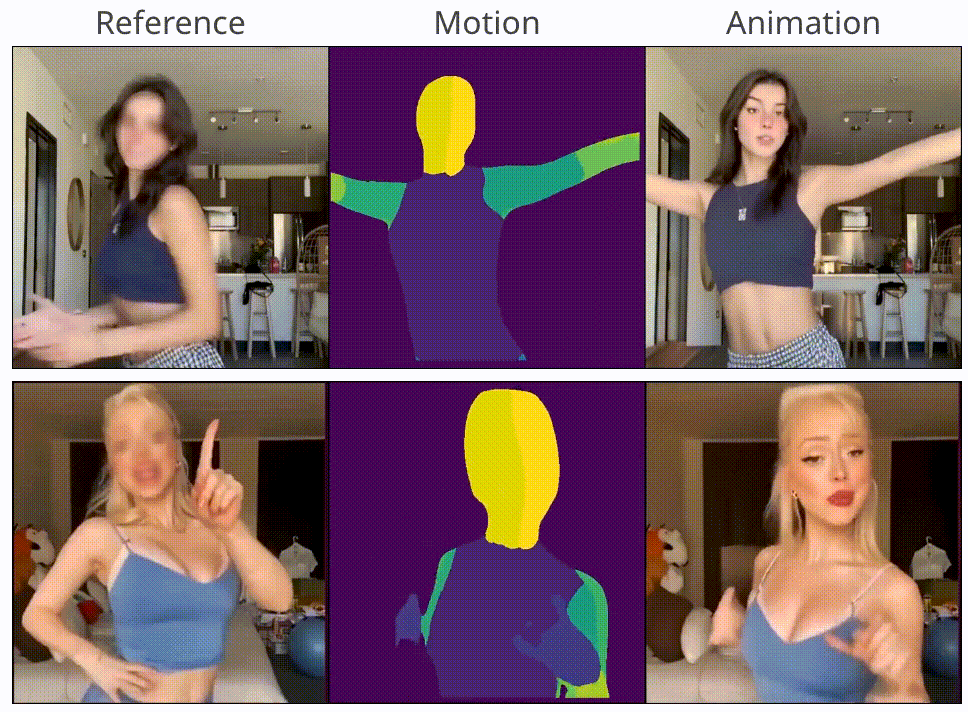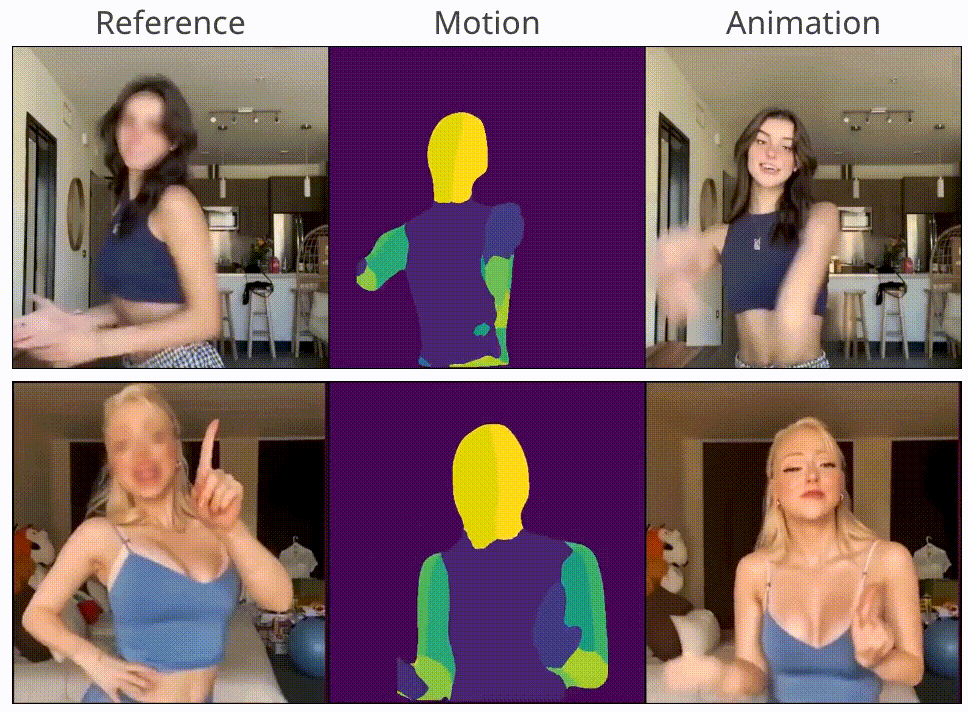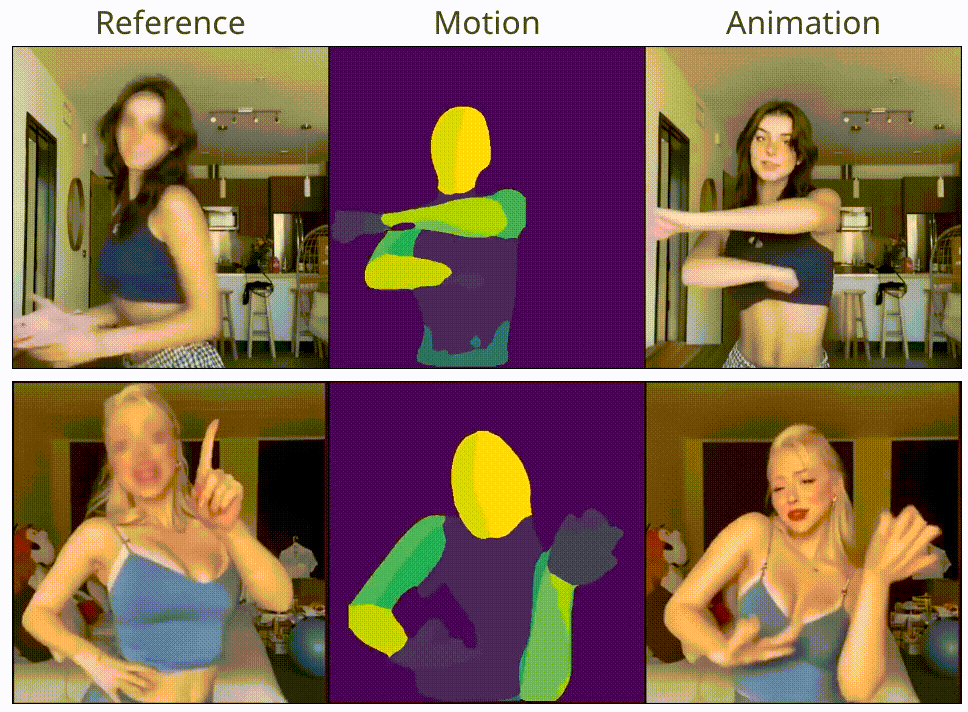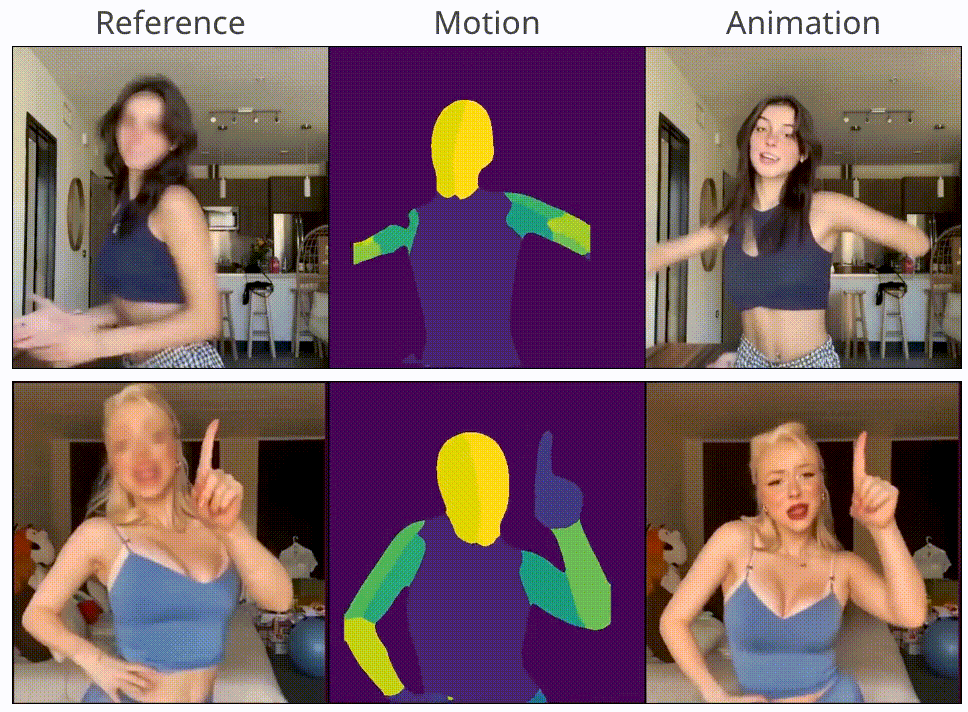
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
Zhongcong Xu, Jianfeng Zhang, Jun Hao Liew, Hanshu Yan, Jia-Wei Liu, Chenxu Zhang, Jiashi Feng, Mike Zheng Shou CVPR, 2024 project page / code / arXiv / HuggingFace demo We propose MagicAnimate, a diffusion-based human image animation framework that aims at enhancing temporal consistency, preserving reference image faithfully, and improving animation fidelity. |
|
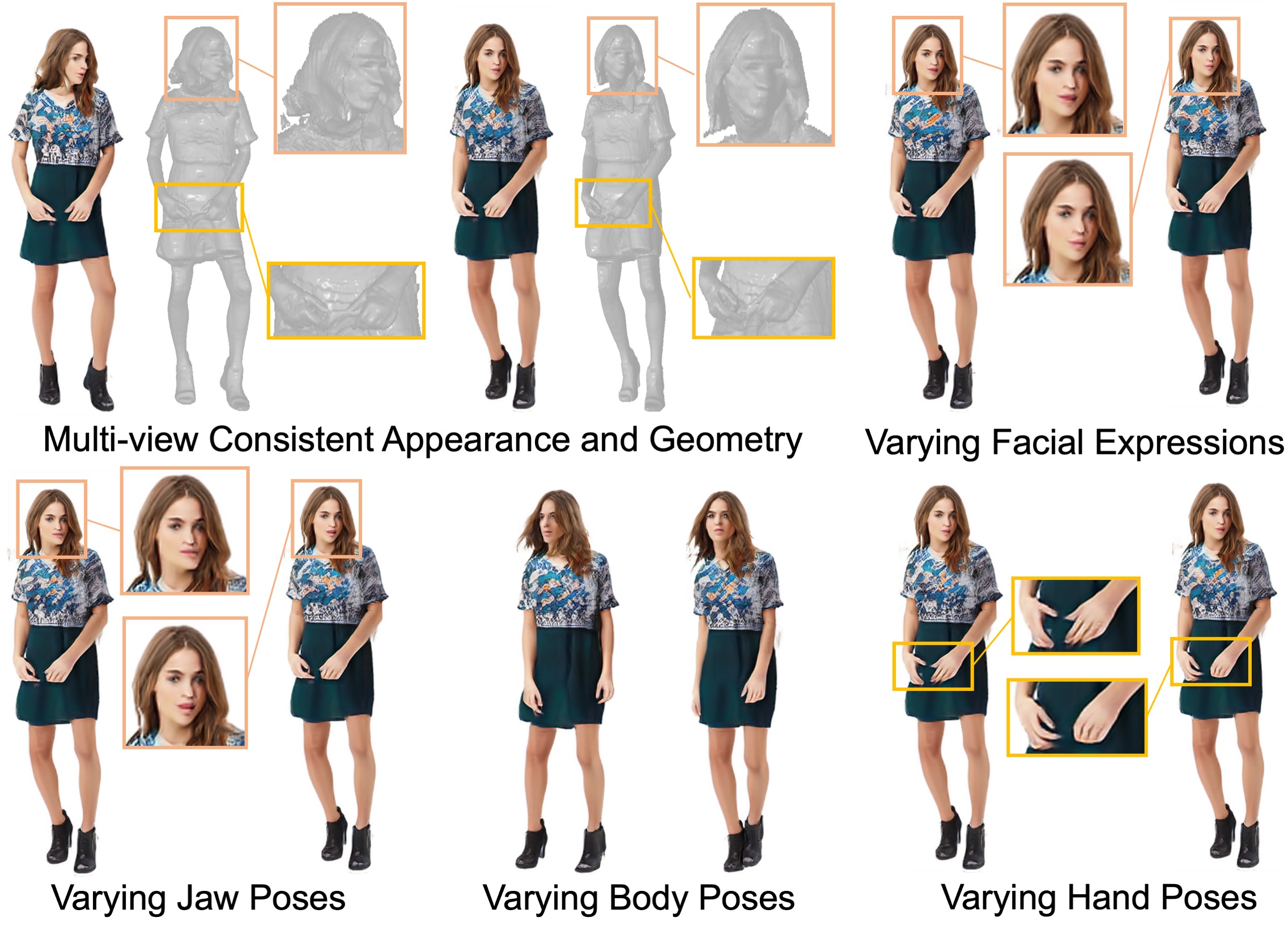
XAGen: 3D Expressive Human Avatars Generation
Zhongcong Xu, Jianfeng Zhang, Jun Hao Liew, Jiashi Feng, Mike Zheng Shou NeurIPS, 2023 project page / code / arXiv XAGen is a 3D-aware generative model that enables human synthesis with high-fidelity appearance and geometry, together with disentangled controllability for body, face, and hand. |
|
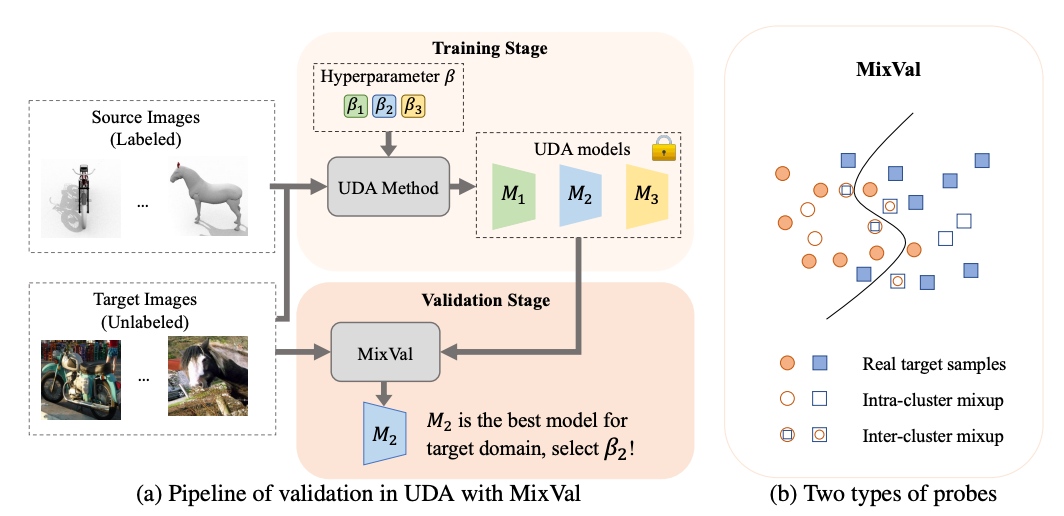
Mixed Samples as Probes for Unsupervised Model Selection in Domain Adaptation
Dapeng Hu, Jian Liang, Jun Hao Liew, Chuihui Xue, Song Bai, Xiaochang Wang NeurIPS, 2023 code / paper We present MixVal, a model selection method that operates solely with unlabeled target data during inference to select the best UDA model for the target domain. |

|
SegRefiner: Towards Model-Agnostic Segmentation Refinement with Discrete Diffusion Process
Mengyu Wang, Henghui Ding, Jun Hao Liew, Jiajun Liu, Yao Zhao, Yunchao Wei NeurIPS, 2023 code / arXiv We present SegRefiner, a universal segmentation refinement model that is applicable across diverse segmentation models and tasks (e.g., semantic, instance, and dichotomous segmentation). |

|
MagicEdit: High-Fidelity Temporally Coherent Video Editing
Jun Hao Liew*, Hanshu Yan*, Jianfeng Zhang, Zhongcong Xu, Jiashi Feng arXiv, 2023 project page / code / arXiv MagicEdit explicitly disentangles the learning of appearance and motion to achieve high-fidelity and temporally coherent video editing. |
|
|
MagicAvatar: Multimodal Avatar Generation and Animation
Jianfeng Zhang*, Hanshu Yan*, Zhongcong Xu*, Jiashi Feng, Jun Hao Liew* arXiv, 2023 project page / code / arXiv / youtube MagicAvatar is a multi-modal framework that is capable of converting various input modalities — text, video, and audio — into motion signals that subsequently generate/ animate an avatar. |

|
MagicProp: Diffusion-based Video Editing via Motion-aware Appearance Propagation
Hanshu Yan*, Jun Hao Liew* Long Mai, Shanchuan Lin, Jiashi Feng arXiv, 2023 arXiv MagicProp employs the edited frame as an appearance reference and generates the remaining frames using an autoregressive rendering approach. |
|
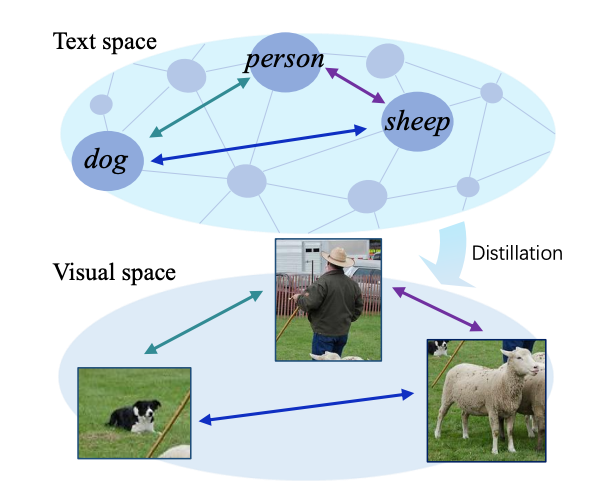
Global Knowledge Calibration for Fast Open-Vocabulary Segmentation
Kunyang Han*, Yong Liu*, Jun Hao Liew, Henghui Ding, Yunchao Wei, Jiajun Liu, Yitong Wang, Yansong Tang, Jiashi Feng, Yao Zhao ICCV, 2023 arXiv We developed a fast open-vocabulary semantic segmentation model that can perform comparably or better without the extra computational burden of the CLIP image encoder during inference. |

|
AdjointDPM: Adjoint Sensitivity Method for Gradient Backpropagation of Diffusion Probabilistic Models
Jiachun Pan*, Jun Hao Liew, Vincent Y. F. Tan, Jiashi Feng, Hanshu Yan* ICLR, 2024 We address the challenge of DPM customization when the only available supervision is a differentiable metric defined on the generated contents. |
|
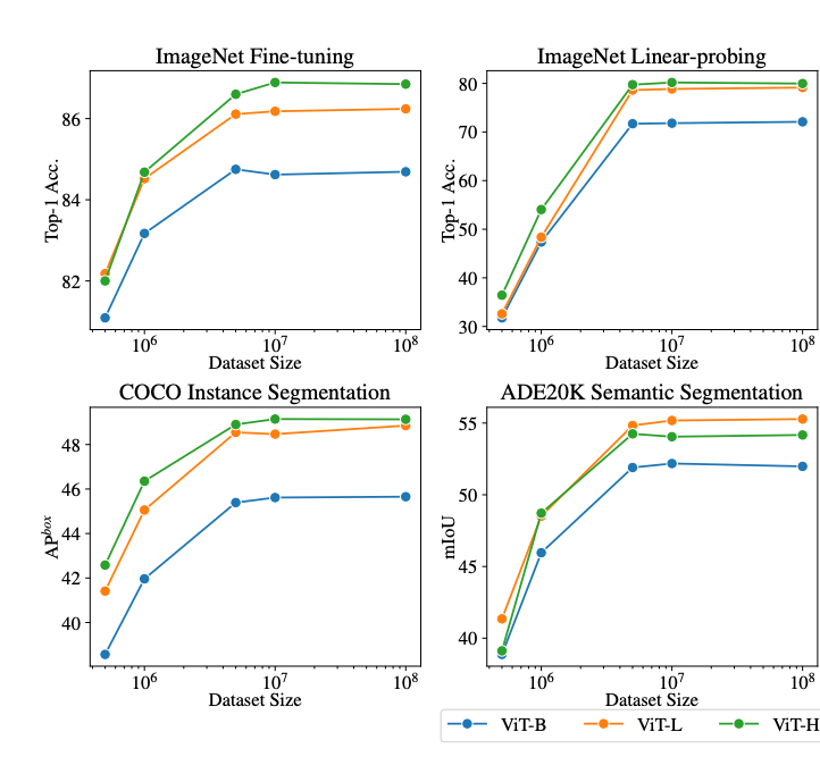
Delving Deeper into Data Scaling in Masked Image Modeling
Cheng-Ze Lu, Xiaojie Jin, Qibin Hou, Jun Hao Liew, Ming-Ming Cheng, Jiashi Feng arXiv, 2023 arXiv We conduct an empirical study on the scaling capability of masked image modeling (MIM) methods for visual recognition. |
|
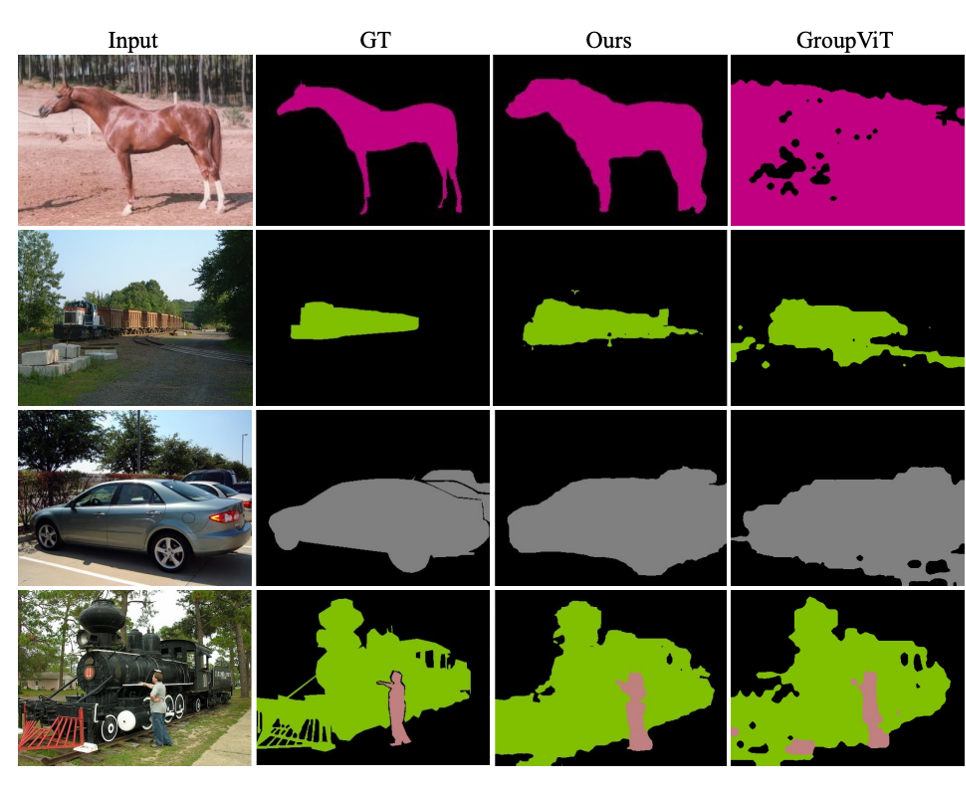
Associating Spatially-Consistent Grouping with Text-supervised Semantic Segmentation
Yabo Zhang, Zihao Wang, Jun Hao Liew, Jingjia Huang, Manyu Zhu, Jiashi Feng, Wangmeng Zuo arXiv, 2023 arXiv Associating spatially-consistent grouping of self-supervised vision models with text-supervised semantic segmentation. |

|
PV3D: A 3D Generative Model for Portrait Video Generation
Zhongcong Xu, Jianfeng Zhang, Jun Hao Liew, Wenqing Zhang, Song Bai, Jiashi Feng, Mike Zheng Shou ICLR, 2023 project page / code / arXiv We propose a 3D-aware portrait video GAN, PV3D, which is capable to generate a large variety of 3D-aware portrait videos with high-quality appearance, motions, and 3D geometry. |

|
MagicMix: Semantic Mixing with Diffusion Models
Jun Hao Liew*, Hanshu Yan*, Daquan Zhou, Jiashi Feng arXiv, 2023 project page / arXiv / code (diffusers) We explored a new task called semantic mixing, aiming at mixing two different semantics to create a new concept (e.g., tiger and rabbit). |

|
Slim Scissors: Segmenting Thin Object from Synthetic Background
Kunyang Han, Jun Hao Liew , Jiashi Feng, Huawei Tian, Yao Zhao, Yunchao Wei ECCV, 2022 project page / paper / code Our Slim Scissors enables quick extraction of elongated thin parts by simply brushing some coarse scribbles. |
|
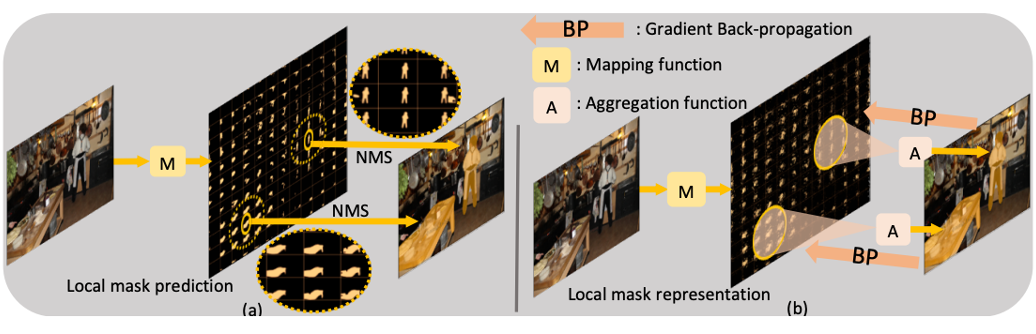
SODAR: Segmenting Objects by Dynamically Aggregating Neighboring Mask Representations
Tao Wang, Jun Hao Liew , Yu Li, Yunpeng Chen, Jiashi Feng TIP, 2021 arXiv We develop a novel learning-based aggregation method that improves upon SOLO by leveraging the rich neighboring information while maintaining the architectural efficiency. |
|
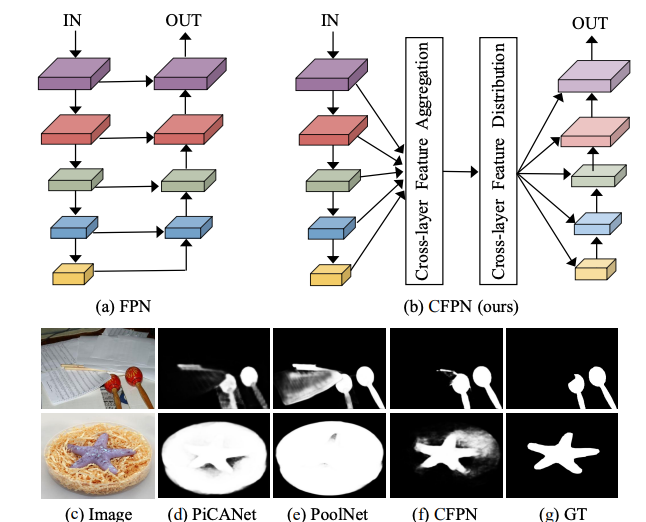
Cross-layer feature pyramid network for salient object detection
Zun Li, Congyan Lang, Jun Hao Liew , Yidong Li, Qibin Hou, Jiashi Feng TIP, 2021 arXiv We identify the issue of indirect information propagation between deeper and shallower layers in FPN-based saliency methods and present a cross-layer communication mechanism for better salient object detection. |
|
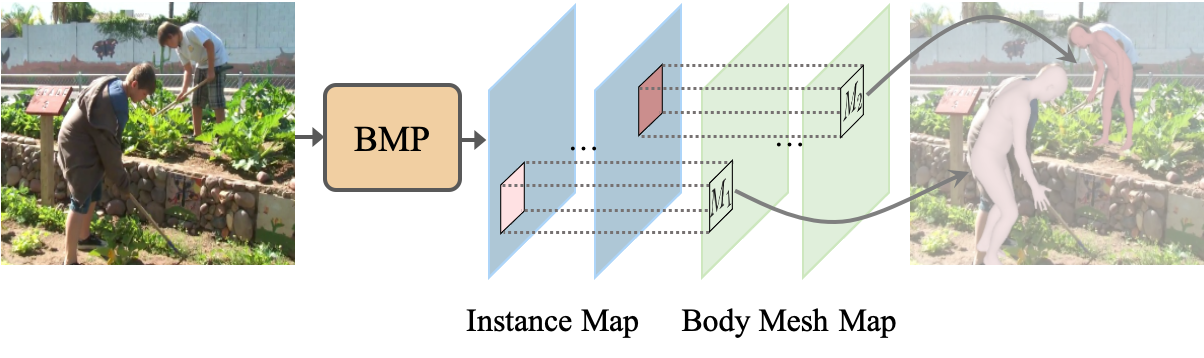
Body meshes as points
Jianfeng Zhang, Dongdong Yu, Jun Hao Liew , Xuecheng Nie, Jiashi Feng CVPR, 2021 arXiv / supp / code We present the first single-stage model for multi-person body mesh recovery. |
|
|
Revisiting Superpixels for Active Learning in Semantic Segmentation With Realistic Annotation Costs
Lile Cai, Xun Xu, Jun Hao Liew , Chuan Sheng Foo CVPR, 2021 paper / supp / code We revisit the use of superpixels for active learning in segmentation and demonstrate that the inappropriate choice of cost measure may cause the effectiveness of the superpixel-based approach to be under-estimated. |
|
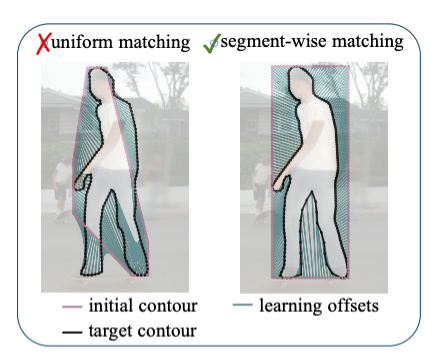
DANCE: A Deep Attentive Contour Model for Efficient Instance Segmentation
Zichen Liu*, Jun Hao Liew*, Xiangyu Chen, Jiashi Feng WACV, 2021 paper / supp / code With our proposed attentive deformation mechanism and segment-wise matching scheme, our contour-based instance segmentation model DANCE performs comparably to existing top-performing pixel-based models. |
|
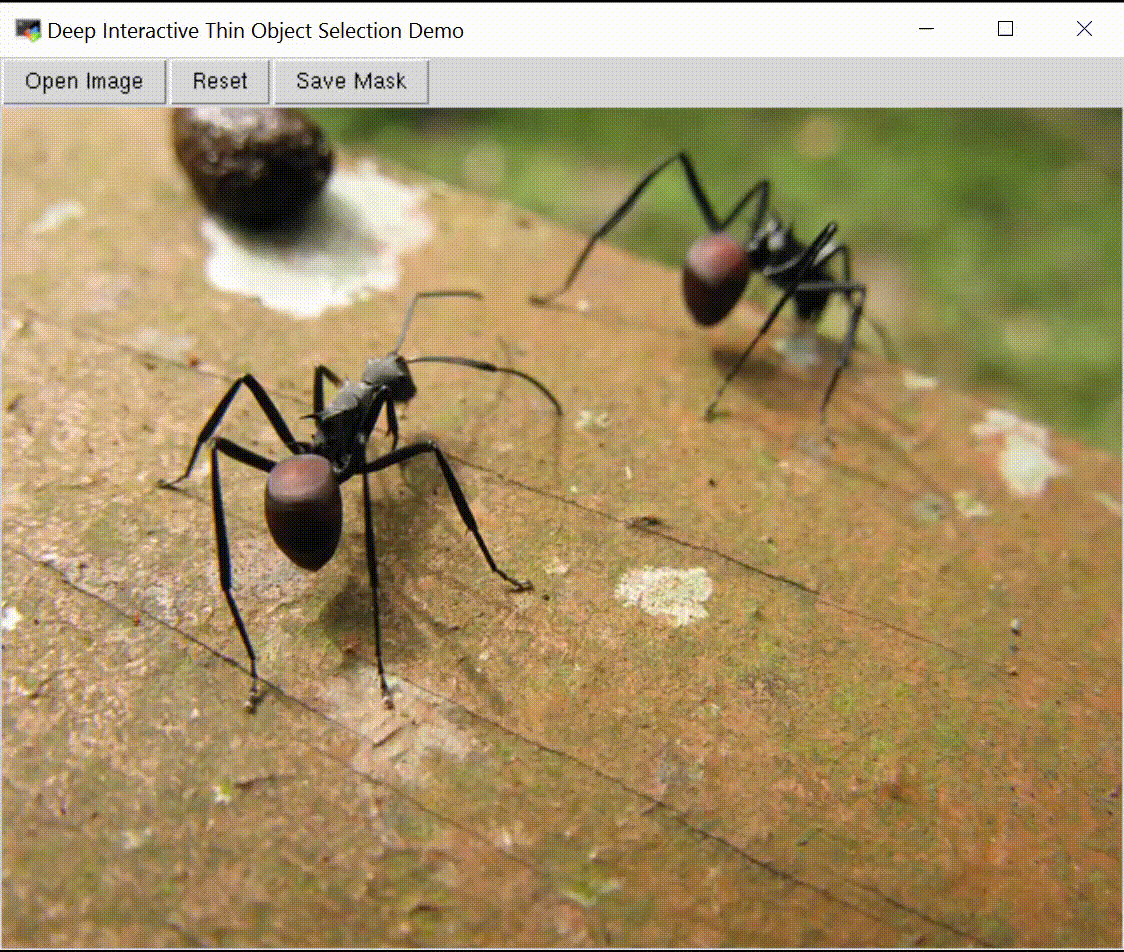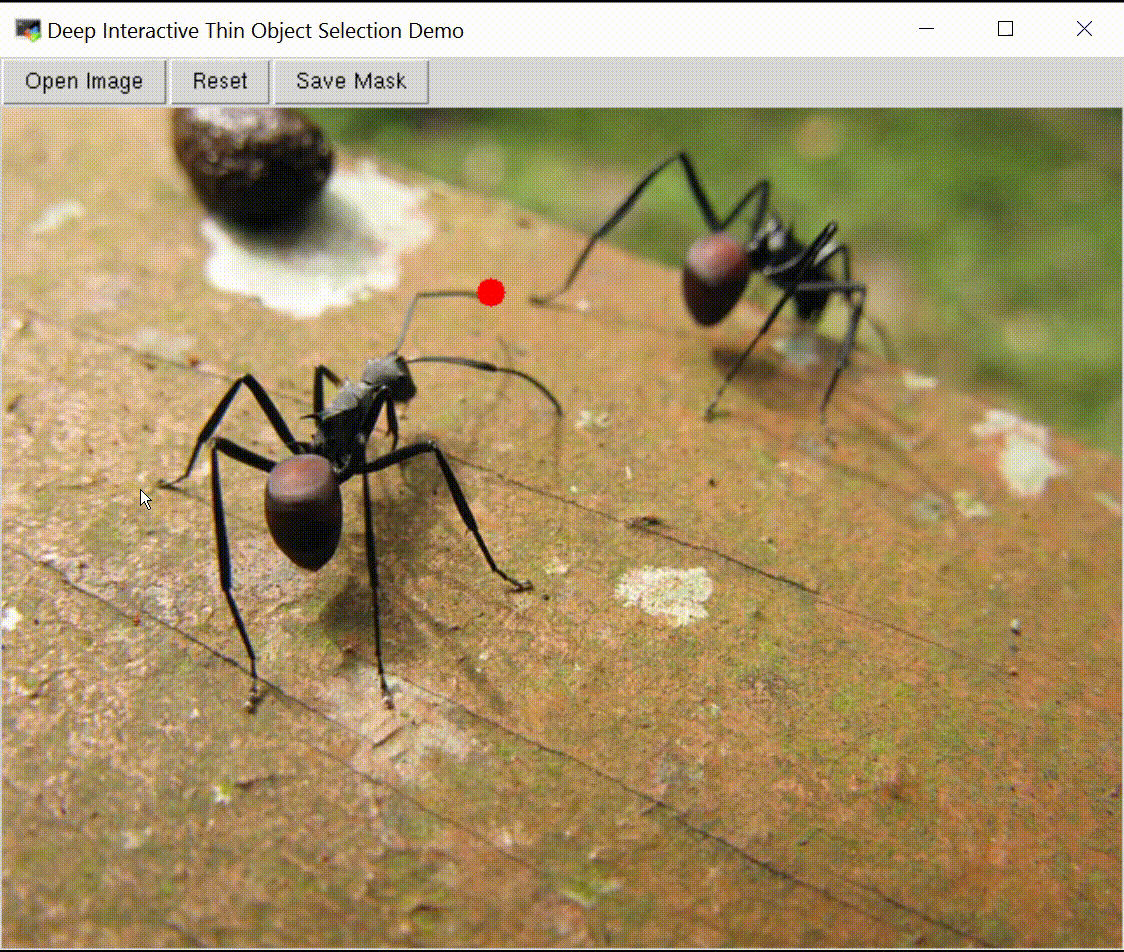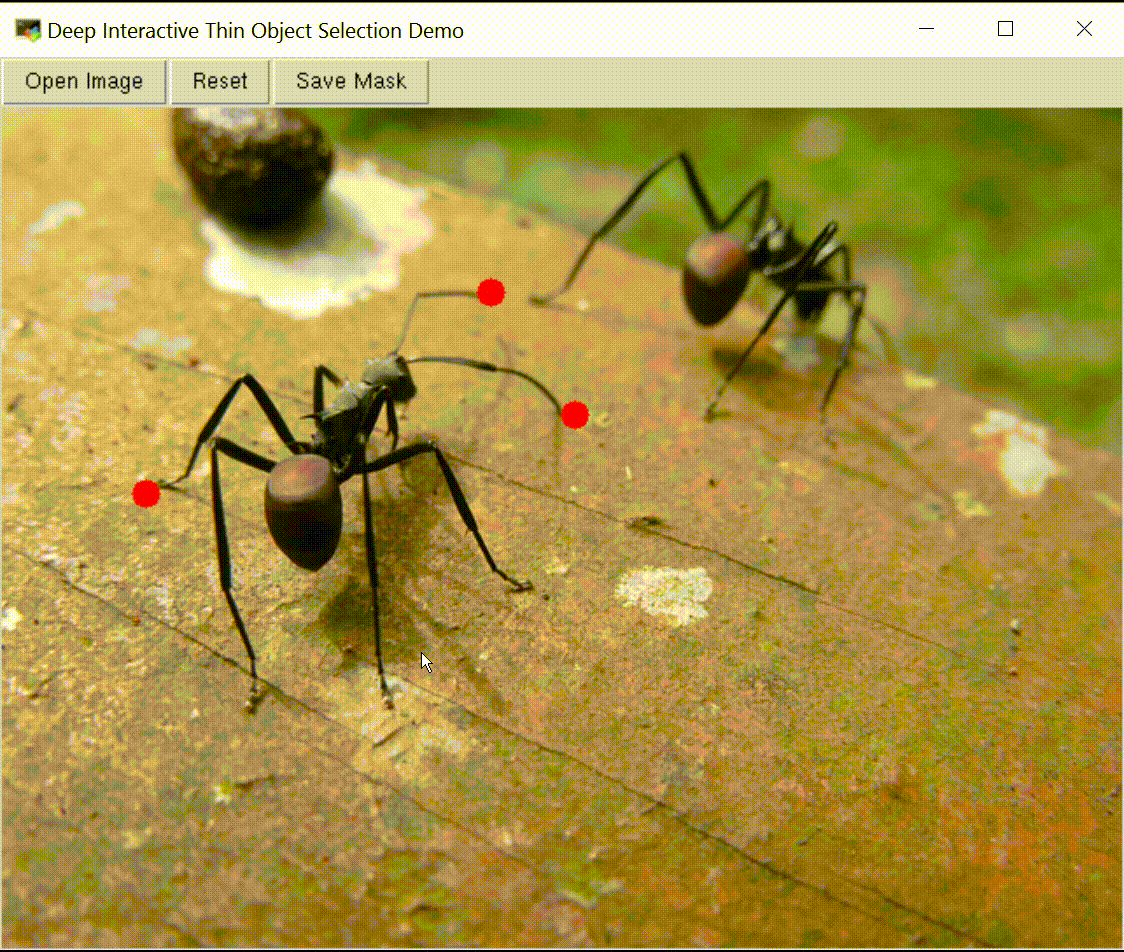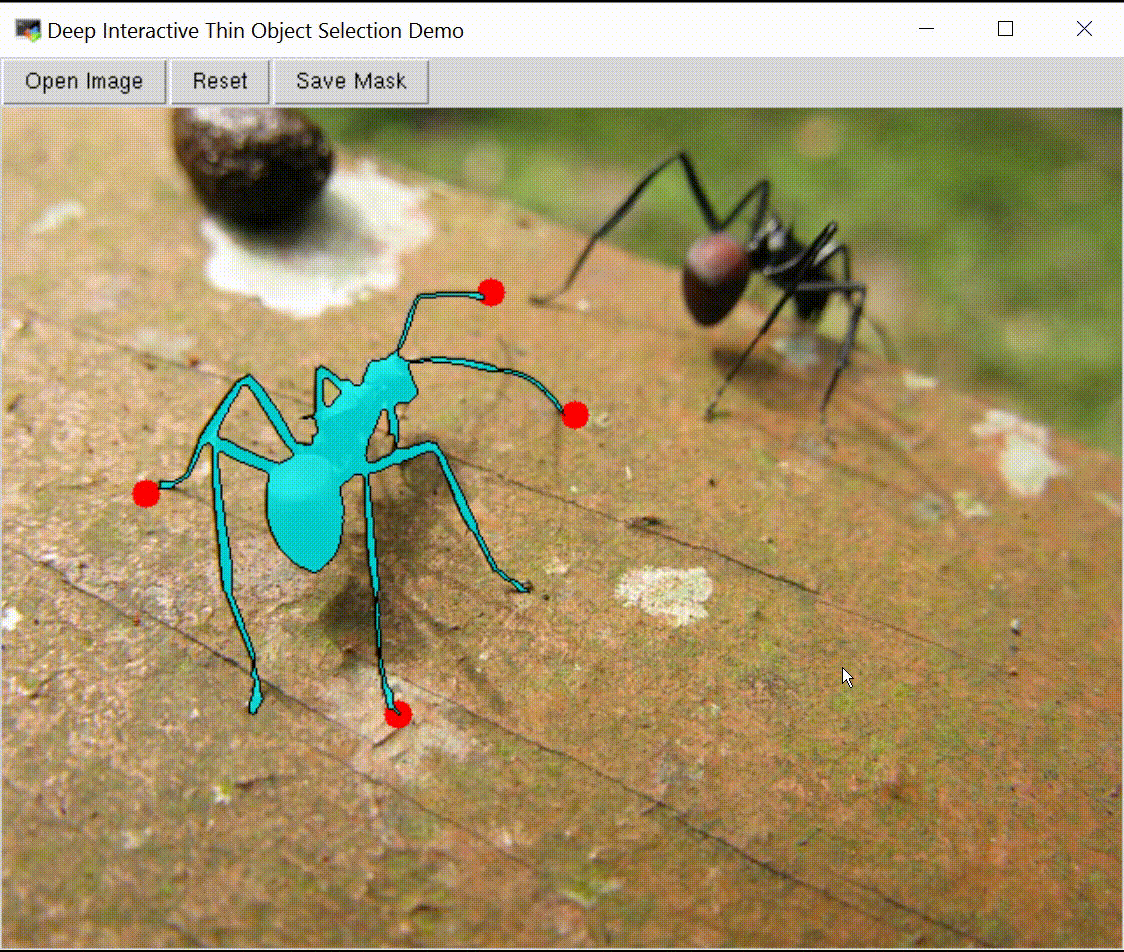
Deep Interactive Thin Object Selection
Jun Hao Liew , Scott Cohen, Brian Price, Long Mai, Jiashi Feng WACV, 2021 paper / supp / code / ThinObject-5K dataset We present ThinObject-5K, a large-scale dataset for segmentation of thin elongated objects. We also designed a three-stream network that integrates high-resolution boundary information with fixed resolution semantic contexts for effective segmentation of thin parts. |
|
The devil is in classification: A simple framework for long-tail instance segmentation
Tao Wang, Yu Li, Bingyi Kang, Junnan Li, Jun Hao Liew, Sheng Tang, Steven Hoi, Jiashi Feng ECCV, 2020 *LVIS 2019 winner arXiv / code We propose a simple calibration framework to more effectively alleviate classification head bias with a bi-level class balanced sampling approach. |
|
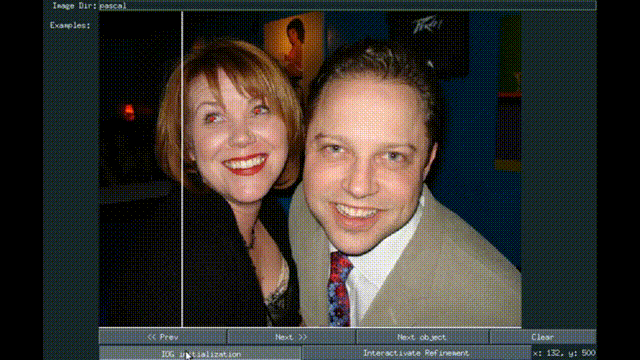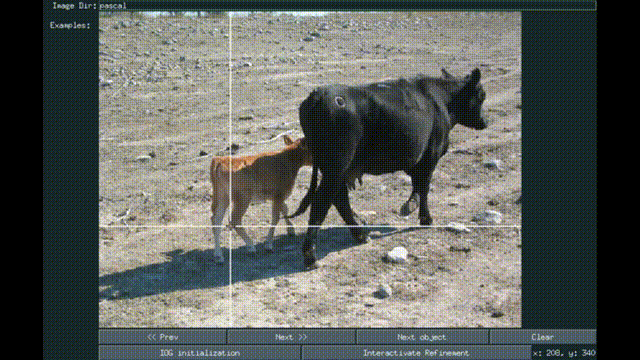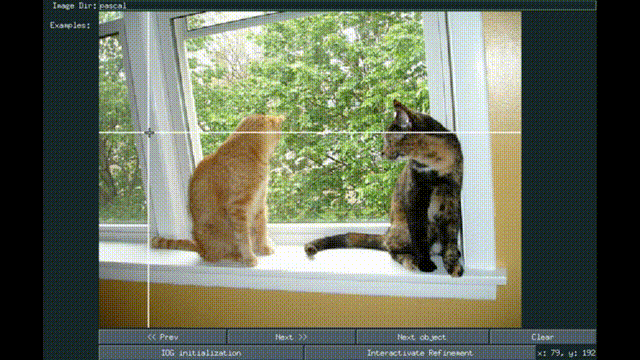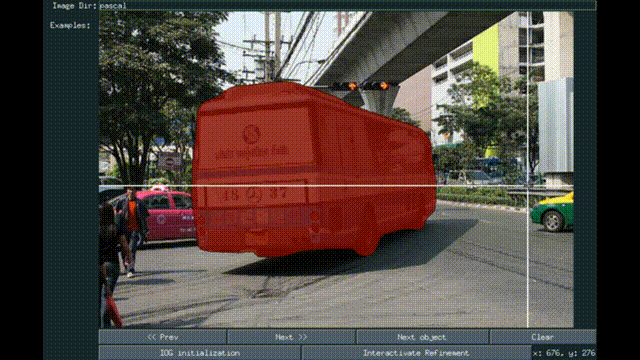
Interactive Object Segmentation With Inside-Outside Guidance
Shiyin Zhang, Jun Hao Liew , Yunchao Wei, Shikui Wei, Yao Zhao, Jiashi Feng CVPR, 2020 *Oral presentation paper / supp / code / Pixel-ImageNet dataset We present a simple Inside-Outside Guidance (IOG) that takes 3 clicks for efficient interactive segmentation. |
|
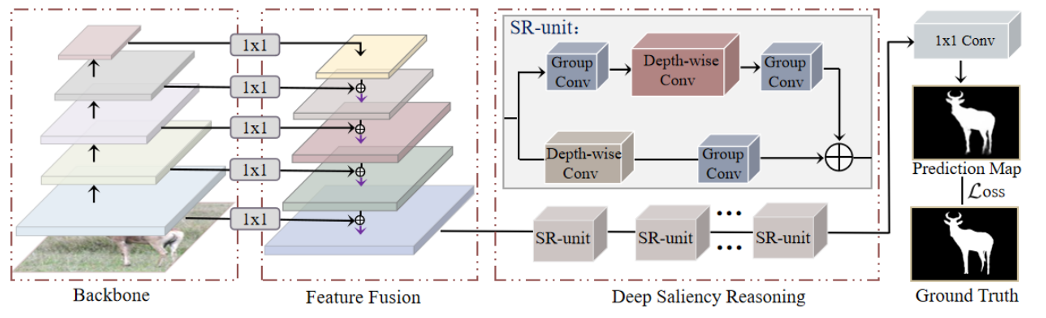
Deep Reasoning with Multi-scale Context for Salient Object Detection
Zun Li, Congyan Lang, Yunpeng Chen, Jun Hao Liew , Jiashi Feng arXiv, 2019 arXiv We propose a deep yet light-weight saliency inference module that adopts a multi-dilated depth-wise convolution architecture for salient object detection. |

|
MultiSeg: Semantically Meaningful, Scale-Diverse Segmentations From Minimal User Input
Jun Hao Liew , Scott Cohen, Brian Price, Long Mai, Sim-Heng Ong, Jiashi Feng ICCV, 2019 paper / supp MultiSeg generates a set of scale-varying proposals that conform to the user input for interactive segmentation. |
|
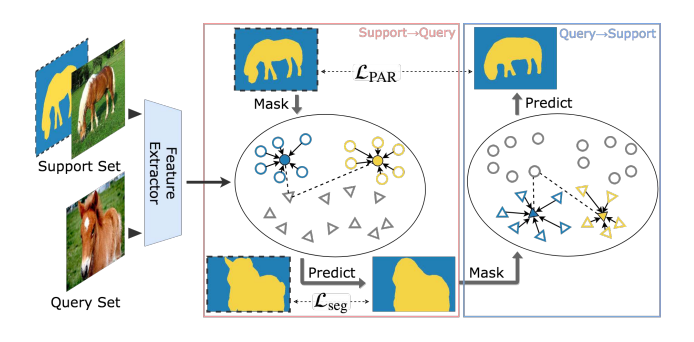
PANet: Few-Shot Image Semantic Segmentation with Prototype Alignment
Kaixin Wang, Jun Hao Liew , Yingtian Zhou, Daquan Zhou, Jiashi Feng ICCV, 2019 *Oral presentation paper / supp / code / video PANet introduces a prototype alignment regularization between support and query for better generalization on few-shot segmentation. |
|
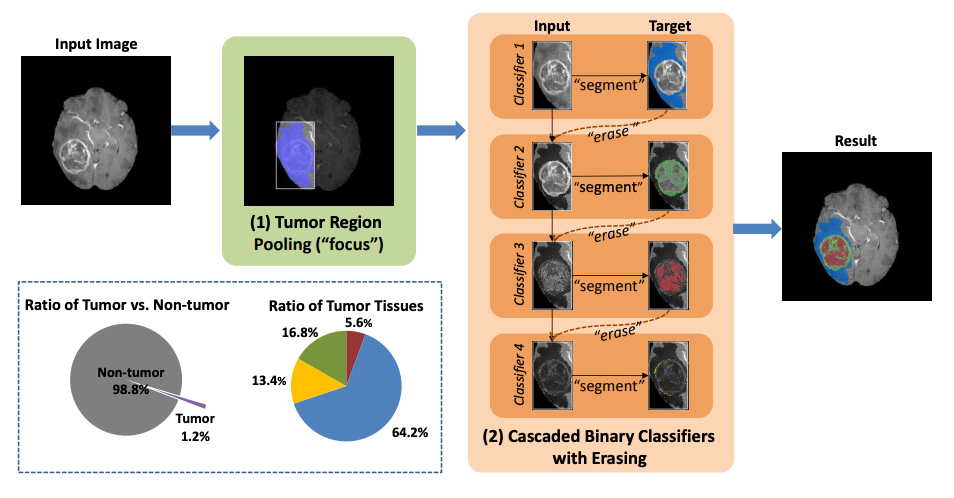
Focus, Segment and Erase: An Efficient Network for Multi-label Brain Tumor Segmentation
Xuan Chen*, Jun Hao Liew*, Wei Xiong, Chee-Kong Chui, Sim-Heng Ong, ECCV, 2018 paper We present FSENet to tackle the class imbalance and inter-class interference problem in multi-label brain tumor segmentation. |
|
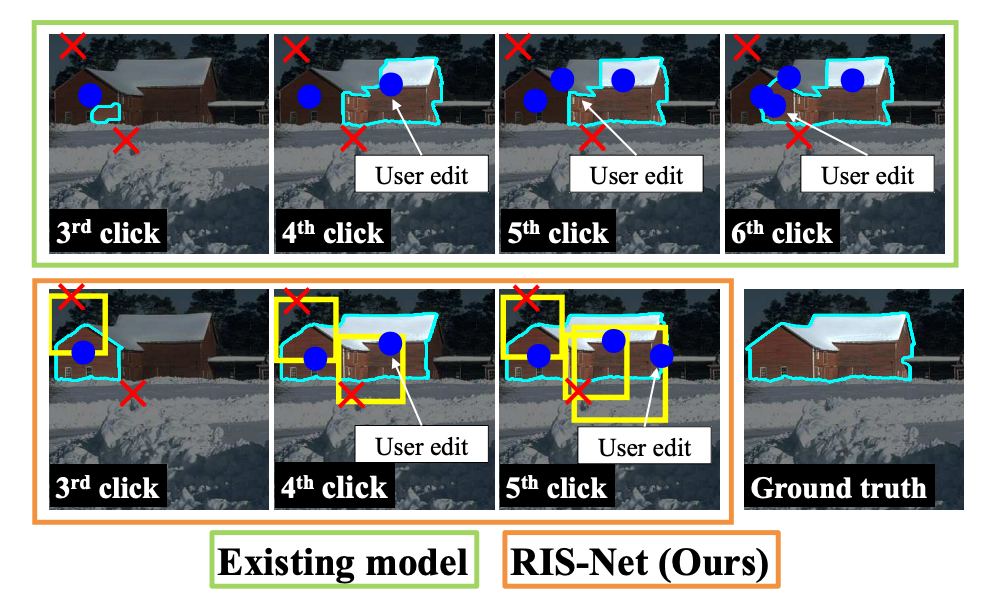
Regional Interactive Image Segmentation Networks
Jun Hao Liew , Yunchao Wei, Wei Xiong, Sim-Heng Ong, Jiashi Feng ICCV, 2017 paper / supp RIS-Net expands the field-of-view of the given input clicks to capture the local regional information surrounding them for local refinement. |